프로젝트 소개
일본인이 만든 재밌는 Ai 프로젝트를 들고와봤다.
https://github.com/w-okada/voice-changer/blob/master/docs_i18n/README_ko.md
실시간 로컬 연산으로 자신의 목소리를 원하는 모델의 목소리로 변조하는 프로젝트다.
무엇보다 출력옵션을 가상 오디오 케이블 프로그램과 연동해 카카오톡, 디스코드, 비디오게임과 연동할 수 있는게 흥미요소다.
시연자 PC의 그래픽카드를 자원으로 쓰기 때문에 (코랩을 이용해 연산할 수도 있다.)
입력(마이크에 들어가는 내 목소리) – 출력(정제된 모델 목소리) 사이 지연시간을 조절해
퀄리티와 응답시간 間 타협을 해야한다.
without gpu 옵션이 있긴 하나 일단 intel utlra 5로는 택도 없다. 아마 Ai라서 외장그래픽카드는 꼭 있어야 할 듯 하다.
그램프로엔 gtx3050이 있어서 써봤는데 상대를 완벽히 속일만큼의 성능을 뽑아내기는 힘들었다.
설치법
실행 방법에는 두 가지가 있는데,
파일을 다운받아서 실행파일로 구동하는 방법과 docker를 이용해 구동하는 방법이 있다.
1. 파일 자체 실행하기
여기에서 다운받아서 파일째로 돌리는 방법이다.
본인이 gpu 있다 -> cuda
없다 -> nocuda
다운받고 start https인가 bat 실행파일 열면 알아서 다 해준다.
만든이 말로는 docker를 사용하는 것이 성능이 훨씬 좋다고 한다. 이렇게 실행하면 그램 프로 기준 으로는 못쓸 정도의 성능이다.
docker를 이용해 실행하기
한국어 자막 키면서 따라하면 된다. 오류가 많이 난다. 오류는 구글링하면 다 나온다.
강좌 영상은 cpu버전 기준이라 실행하면 gpu를 못잡는다고 오류날텐데, 그 오류 구글에 검색하면 nvidia 뭐시기 라이브러리 까는법 다 나온다.
docker라는 개념을 처음 접했는데 가상 리눅스 뭐 이런거인듯? 암튼 체감상 도커를 통하면 성능이 낫다.
영상속에선 git clone 할때 버전을 뒤에 쓰는데 똑같이 따라하면 모델도 없는 이상한 구버전 다운받아짐. 걍 깃허브에서 url 복사해서 다운받으세요

터미널 열어서 wsl 들어가고
cd로 깔아둔 voice changer 폴더 들어가신다음
bash start_docker.sh 치면 실행됩니다.
컨트롤 누르고 저기있는 https://127.0.0.1:18888 누르면 html로 만든 gui 나옴
voice changer 사용법
크롬에서 안전하지 않다 뭐시기 뜨면 고급설정에서 안전하지 않음으로 이동 누르세요
그리고 터미널이 본체기에 계속 띄워놓으셔야합니다?
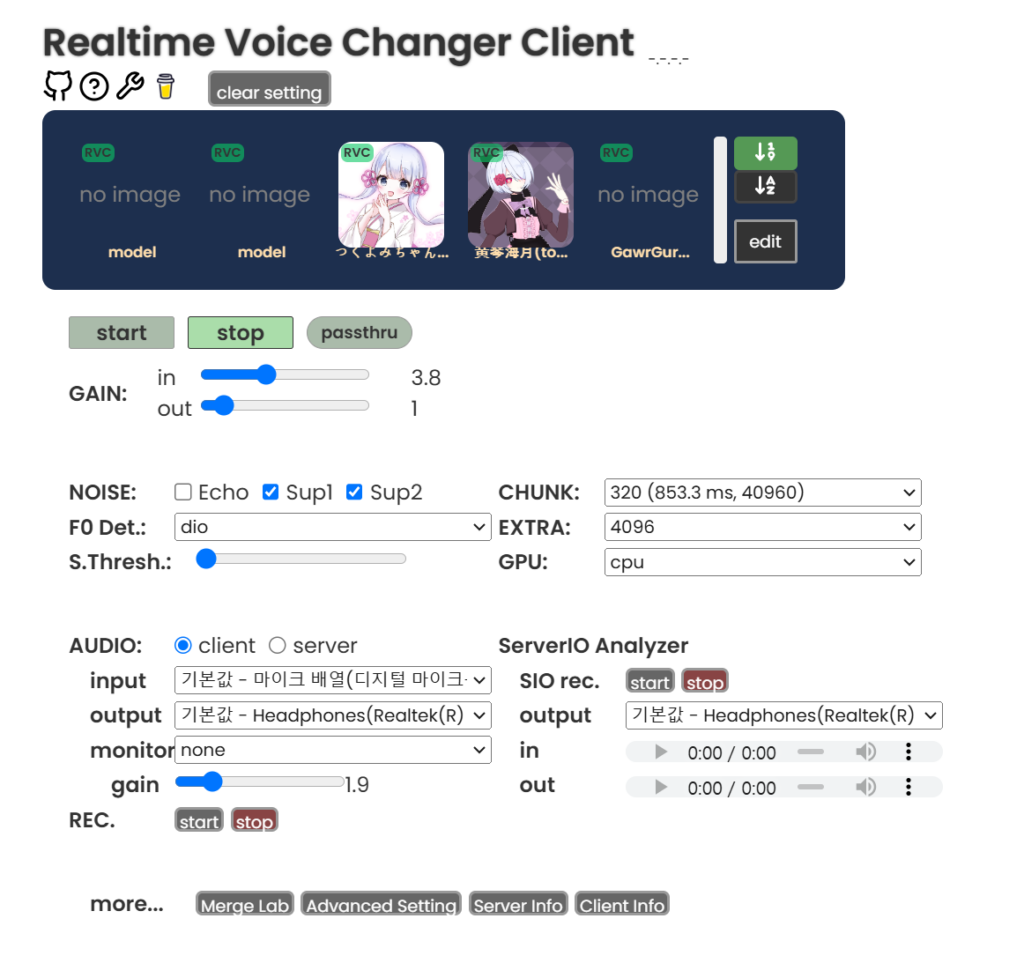
처음엔 모델이 없을텐데
edit – dlsample 들어가면 샘플 모델 몇개 있습니다. 다운받으시면 됨.
다운 안되고 터미널에 뭐시기 뜨는 경우가 있던데 저같은 경우는 걍 바탕화면에 wsl 만드니까 됐습니다. 권한 문제인듯?
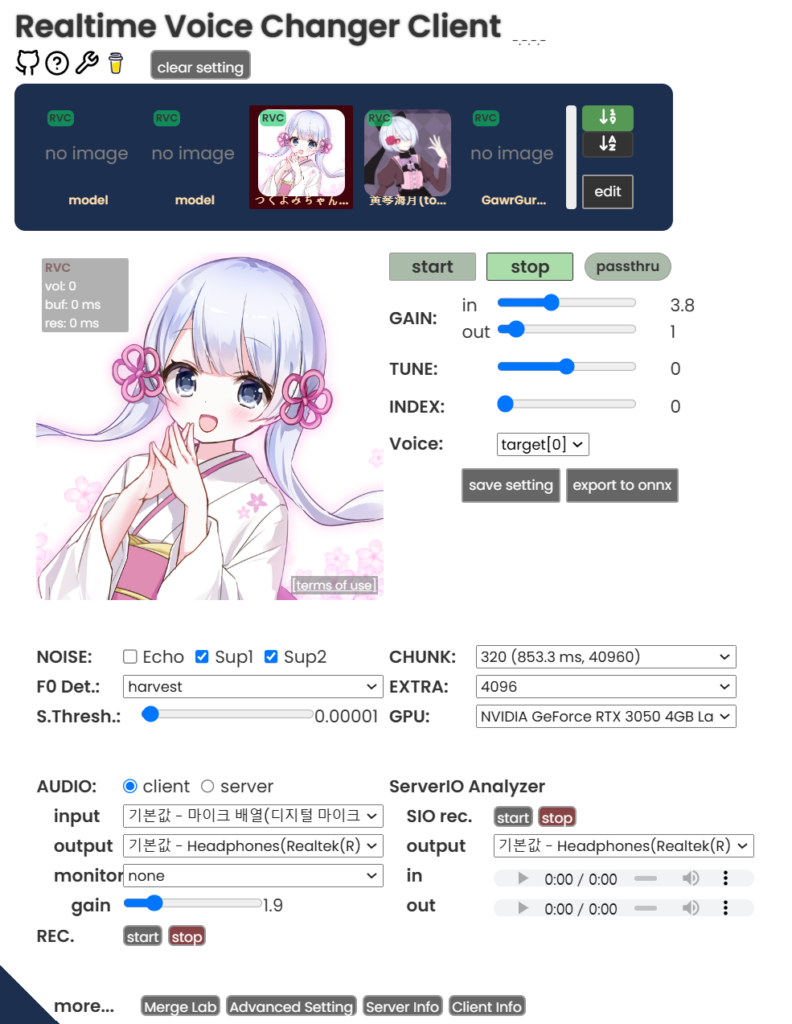
모델 클릭하면 이렇게 뜨는데… start 누르면 준비 완료임…
옵션 설명
Gain: 입력 출력 음량. 내 말이 씹히는거같으면 in을 높히세요
tune: 출력의 목소리 톤 조절. 남자->여자면 12가 적당한듯
index: 모델의 말투같은 걸 반영하는가본데, 예를 들어서 봇치 모델 쓰고 이거 높히면 봇치 특유의 찐따 억양이 강해짐. 근데 연산을 많이 잡아먹는지 값이 높을수록 못 쓸정도로 버벅입니다.
Noise: 잡음 제거 옵션인데 다 키는걸 추천
F0 Det.: 연산 모델인거같은데 rmvpe가 제일 자연스러운듯. 아마 rmvpe가 nvidia 전용 모델일거에요.(아님말고)
S.Thresh: 모르겠음요 기본값으로 두는중
CHUNK: 이게 가장 중요한 지연(계산)시간인데, gpu 성능에 크게 좌우되는거같음. 진짜 자연스러우려면 적어도 1초안에 내 말이 상대방한테 가야하는데 그램프로기준 768(2초정도)까지 늘려야 안버벅이고 자연스러움
extra: 내 말을 얼마나 오래 입력받냐 이런거같은데 값이 높을수록 한번에 많이 말해서 한꺼번에 변조할 수 있습니다. 실시간 대화라면 짧을수록 좋겠죠
input은 내가 대고 말할 마이크겠죠
out은 스피커로하면 변조된 목소리를 나만 듣겠죠
그래서 가상 오디오 케이블을 쓰면 변조된 목소리를 원하는 프로그램으로 보낼 수 있습니다.
프로그램을 다운받아서 설치하고?

output을 가상 케이블로 한다음?

(PC 카카오톡의 보이스톡 옵션)
원하는 프로그램 마이크를 가상케이블로 해주면?
변조된 목소리가 입력이 됩니다.
보이스 모델은 여기가서 다운받으시오.
그런데 모델 학습 베이스가 영어, 일본어라서
한국어 특유 발음( ㅚ, ㅞ, 받침 ㄹ)을 하면 뭉개지는 경우가 빈번함.
한국 아이돌 모델도 동일
근데 노무현, 윤석열은 이상하게 기가 맥히게 자연스럽더라..
암튼 저는 그램프로라 넷카마질을 할 수는 없지만…
본인 컴퓨터가 한 성능한다 <- 꼭 해보십시오
그래픽카드가 사고싶어지는 저녁이다..